![[스파르톤-3rd 생존일지] 나 이제 웹스크레핑이랑 데이터 분석 및 시각화 할 수 있어~! 쏠 수 있어~!!](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbHPiIv%2FbtrMkQYcwBt%2FAAAAAAAAAAAAAAAAAAAAAPrRxRhagv5Cy0rHutCRxlPeSO_XjYt1UD1W0_VAJ70H%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DjM7MW5%252BOMSKNwWaX3Fk%252Bwz%252B23O4%253D)

[2022.08.17 10:55] 스파르타 코딩클럽에서 미리 보내주신 스파르톤 키트와 함께 스파르톤의 시작을 기다렸다..!
스파르톤 후 휴식 때 쓰라고 보내주신 안대와, 스파트론 진행 시간동안 심심한 입을 달랠 커피와 초콜릿 사탕 그리고 원기 회복을 위한 박카스 젤리까지..! 시작부터 신나는 밤샘코딩이다..!

[11:00-11:10] 광장에서 오프닝 간단한 타임라인 소개와 진행 방법 안내 후 다함께 강의실로 이동했다!

[11:10-11:20] 조 편성 및 이름 정하기 : "B-3 졸리지만 안잔다조"

[11:20-11:30] 밤새 공부할 강의 선택(스파르톤 무료강의-파이썬 웹 스크래핑, 시간이 남으면 데이터 분석까지!)
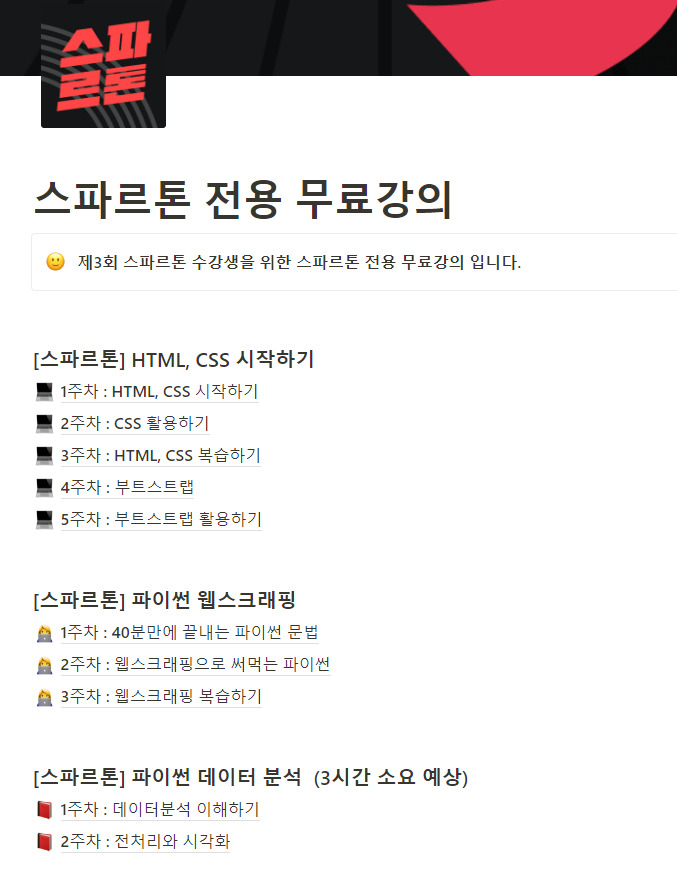
[12:00] 오랜만에 다시 보는 파이썬의 편리함에 취해 어느새 12시가 된지도 모르고 있었다!
현재 진도는 파이썬 웹스크레핑에 1주차 파이썬 문법 강의를 듣고있다. 파이썬은 진짜... 사랑스러운 언어같다...! 오늘 일어난지 벌써 18시간이 넘어가서 그런지 조금 멍한 감은 있지만, 기분도 좋고 강의듣고 하나씩 해보는 것도 참 즐겁다..!
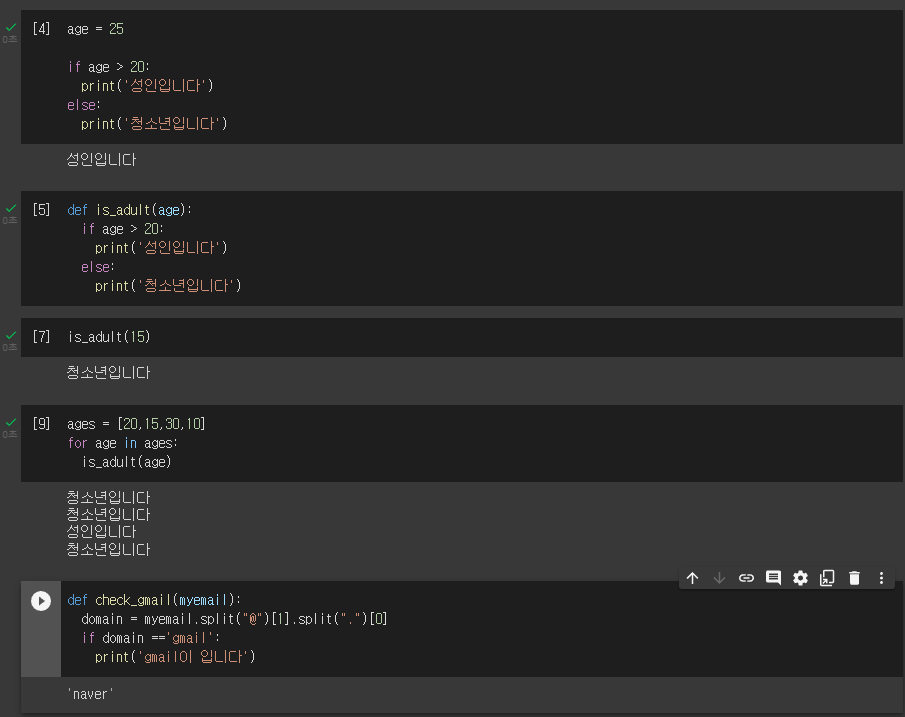
[12:24] 파이썬 라이브러리 설치 / selector 사용해 필요한 내용 절삭
!pip install #라이브러리 설치
#라이브러리 설치 예시
!pip install requests bs4 #requests와 bs4라는 라이브러리를 설치해줘
#크롤링 기본 코드
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')1] 1개의 기사 가져오기
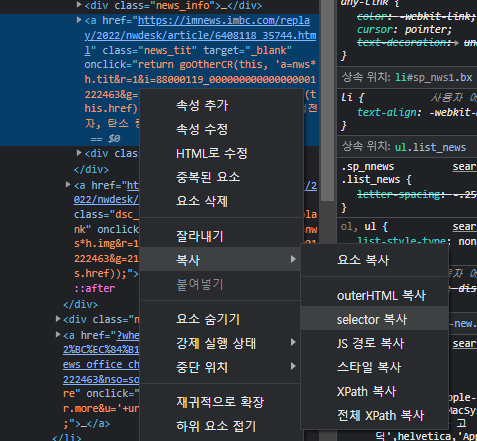

2] 기사 여러개 가져오기 : ul태그의 selector 가져오기


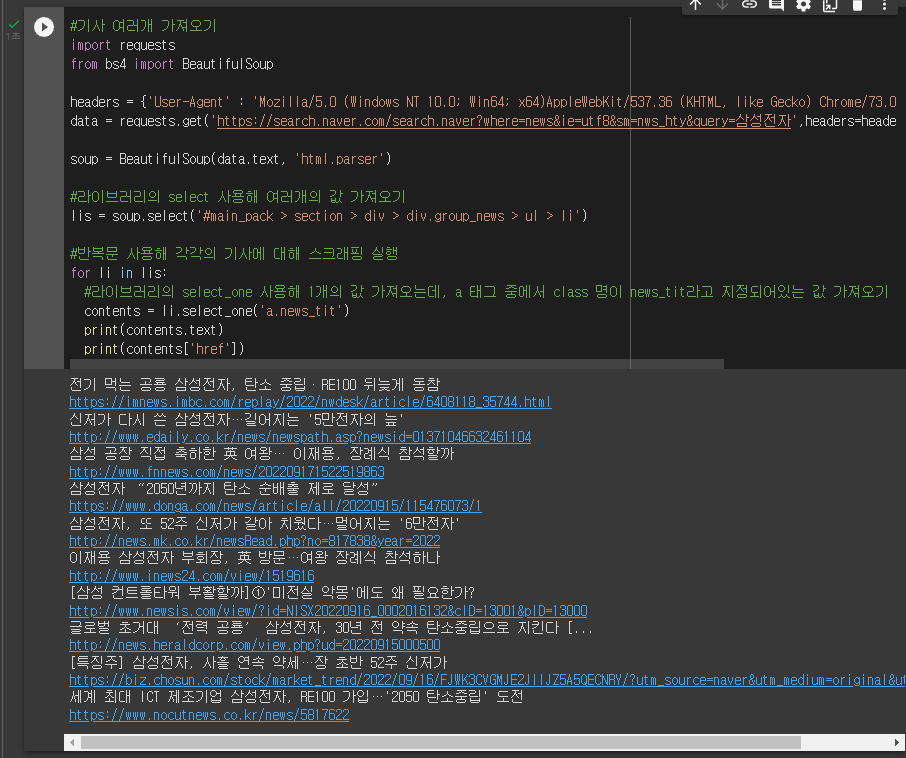
[13:00] 기사 여러개 스크래핑을 시도하던 중 웨않되 를 마음속으로 외치는 중에, 매니저님께서 벌써 1시가 되었음을 알리셨다. 시간이....! 아주 빨리간다...! 역시 시간 보내는데에는 에러만한게 없지...! 아직까지는 아주 즐거운 기분으로 공부를 진행하는 중이다. 같이 캠스터디를 진행하는 백엔드 친구에게도 한 번 배워볼것을 권하며.. 다시 에러 잡으러 가야지!
3] 함수로 만들어 여러가지 키워드 스크래핑이 가능한 함수 만들기

4] 응용편(언론사 명 추가하기)

[01:45] 응용문제까지 끝냈는데, 왠지 곧 생존일지를 제출하라고 할 것 같아서 겸사겸사 미리 한 자 적어본다. 에러를 만난다거나, 새로운 문제를 받으면 집중력이 빰빰 빵빵해지는 느낌이라 아직까지도 완전 쌩쌩하다..! 진짜 즐거운 밤이다!
[2:00] 대망의 스파르톤 OX게임 시작..! 사람 정말 많다...! 이 많은 사람들이 코딩을 하기 위해 모였다니!

[2:38] 게임.. 재밌는데 아무래도 게임을 잘 못하다 보니, 오히려 코딩할 때 보다 조금 잠이 오는 것 같아서, 좀비게임, 색칠하기게임 등등 게임방을 한 바퀴 돌아보고는 바로 강의실로 복귀했다..! 그래도 메타버스에서 이런저런 체험을 해볼 수 있음에 감사했던 40분의 휴식이었다..!
5] 네이버 영화 웹 스크레핑(랭킹, 제목, 별점 가져오기)


YANA's 문제풀이 시작
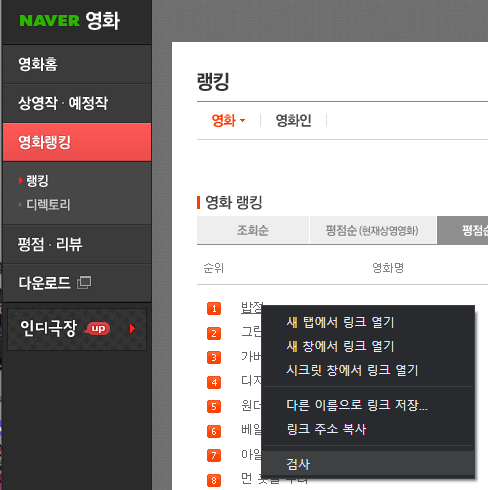
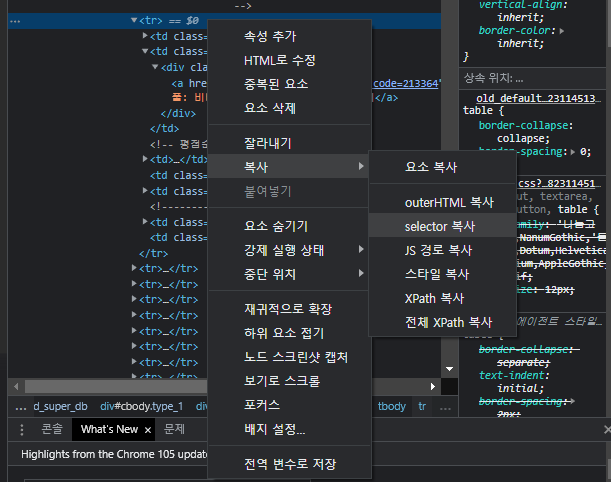
- 복사된 selector(#old_content > table > tbody > tr:nth-child(2))의 경우 tbody내부의 2번째 tr만 가져옴.
- 따라서, 몇번째 자식 요소인지를 표현하는 ':nth-child(2)'는 지움으로써, 서버에서 받아온 자료에서 'old_content 라는 id를 가진 요소 내부의 table 의 tbody의 tr들'의 정보를 받아온뒤 자료의 형태를 확인한다.
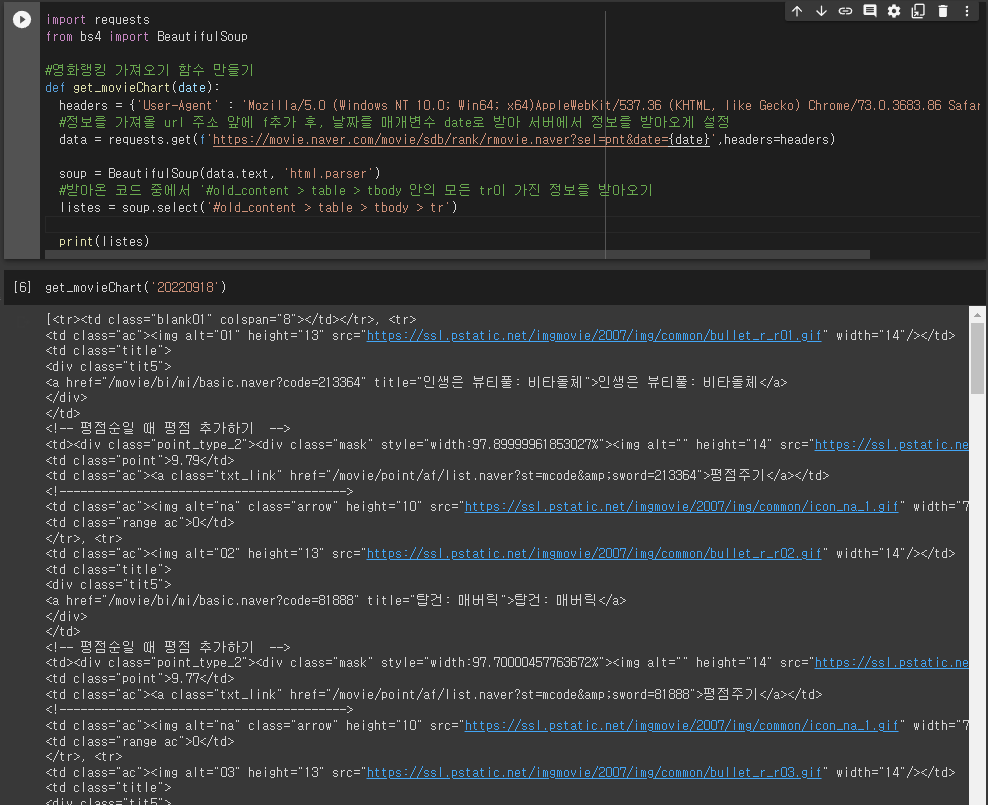

1) 순위 : tr내의 td 중 'ac'라는 클래스를 가진 td 안 img 태그의 'alt'속성
2) 제목 : tr내의 첫번째 a태그의 'text'값 / tr내의 td 중 'title'라는 클래스를 가진 td 안 a태그의 'text'값
3) 평점 : tr내의 td 중 'point'라는 클래스를 가진 td의 'text'값
[3:00] 게임을 마치고 사람들이 전부 강의실로 복귀했는데, 생각보다 지금까지도 남아있는 사람들이 아주 많았다. 이렇게 많은 사람들이 다들 개발이라는 같은 분야에 관심을 가지고 모여 함께 하루 밤을 꼬박 새우며 공부할 수 있다는 점이 문득 신기했고, 뭔지 모를 동질감이 들면서, 오늘 모인 수많은 사람들이 '같은 뜻을 가진 동료들이구나' 하는 생각이 들었다.
import requests
from bs4 import BeautifulSoup
#영화랭킹 가져오기 함수 만들기
def get_movieChart(date):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
#정보를 가져올 url 주소 앞에 f추가 후, 날짜를 매개변수 date로 받아 서버에서 정보를 받아오게 설정
data = requests.get(f'https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date={date}',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#받아온 코드 중에서 '#old_content > table > tbody 안의 모든 tr이 가진 정보를 받아오기
movieList = soup.select('#old_content > table > tbody > tr')
#받아온 순위별 영화 정보가 담긴 tr들에 대해서 아래를 반복 실행
for movie in movieList:
if movie.select_one('a') is not None:
#순위 : 1) tr내의 첫번째 img태그의 alt값 / 2) tr내의 td 중 'ac'라는 클래스를 가진 td 안 img 태그의 'alt'속성
rank = movie.select_one('img')['alt'] #movie.select_one('td.ac').select_one('img')['alt']
#제목 : 1) tr내의 첫번째 a태그의 'text'값 / 2) tr내의 td 중 'title'라는 클래스를 가진 td 안 a태그의 'text'값
title = movie.select_one('a').text #movie.select_one('td.title').select_one('a').text
#평점 : tr내의 td 중 'point'라는 클래스를 가진 td의 'text'값
star = movie.select_one('td.point').text
print(rank+" "+title+" "+star)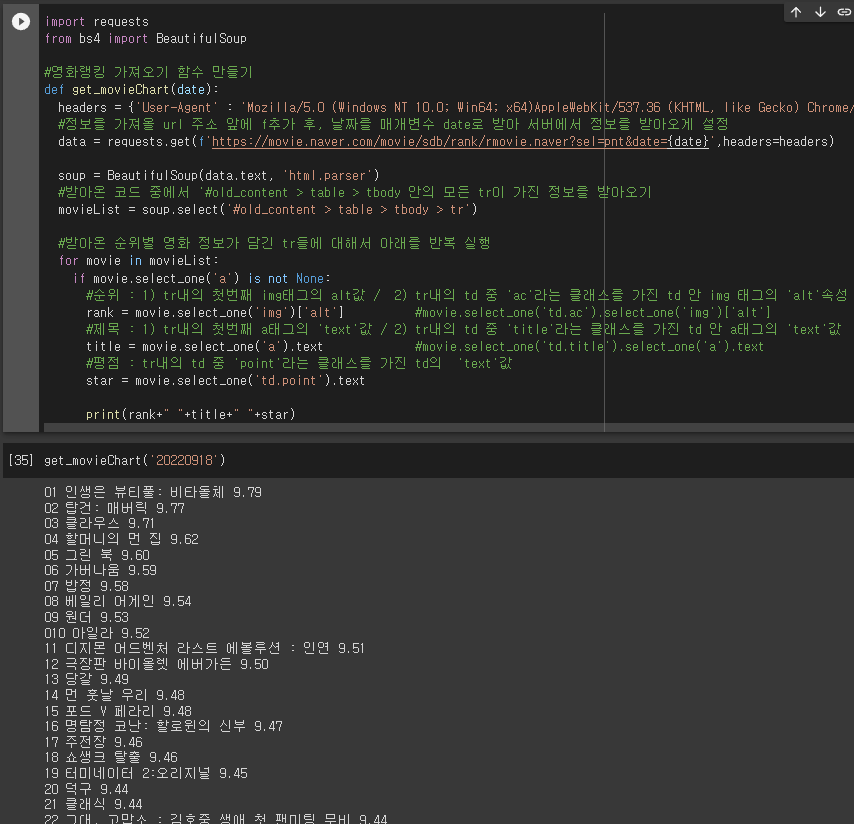
[03:41] 매니저님의 생존 확인과 함께 웹스크레핑 복습 강의까지 완강 완료오...! 이젠 파이썬 데이터분석을 시작해보고자 한다! 종료시간 전에 데이터 분석도 완강 할 수 있겠지..? 1.25배속의 힘을 믿어보쟈..!
[03:56] 강의에서 다시 한 번 파이썬 기초 문법 강습이 나오는 틈을 타, 메타버스 내의 졸음쉼터를 방문했는데...! 했는데..! 졸음쉼터라면서요...! 졸음쉼터라면서....!!! ㅋㅋㅋㅋㅋㅋㅋㅋㅋ 다 울었으니 이제 코딩하러 갈게요..ㅠ

[04:10] B섹션 게임 시작..! 스파르톤이라는 이름에 걸맞게 마라톤 게임을 진행한다고 한다! 이건 이겨야지..!

[04:20] 게임이 끝나고 강의실로 돌아와, 같은 조 사람들과 찌르기 놀이?를 하면서 놀다가 다시 강의를 듣기 시작했다. 낮선 사람과 찌르기 하나만으로도 10분을 놀 수 있는 이 곳은 바로 스파트론. 굿.
이번 강의에서는 jupqter notebook을 통한 파이썬 코딩을 진행한다고 해서 오랜만에 주피터 노트북을 켜봤다..!

첫번째 강의는 파이썬 기초문법이라 간단히 문제만 풀고 넘어가본다..!

1] 파이썬 라이브러리 pandas 의 import (계속 입력하기엔 너무 기니 pd로 부르기러 한다.)
import pandas as pd2] 사용할 데이터를 불러온다
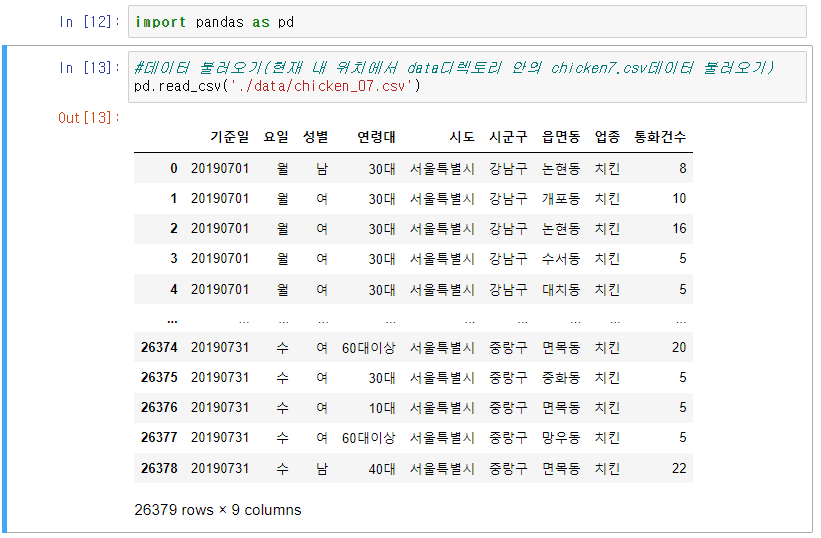
3] 데이터 확인( 끝 데이터 확인 tail(n), 데이터 기본 통계치 확인 describe() )
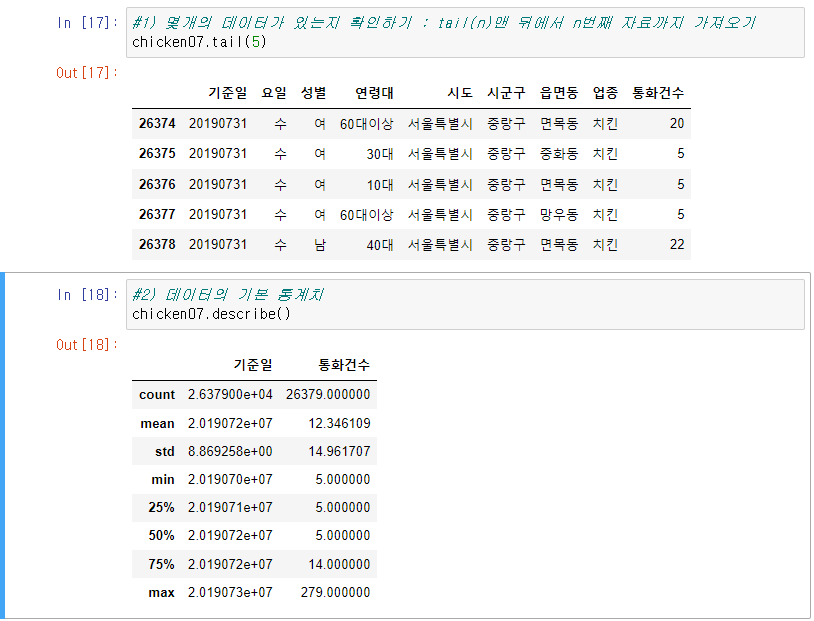
4] 간단한 데이터 열람(컬럼별 값, 데이터의 종류와 그 수의 확인)

5] - 1) 데이터 합치기 : concat([합칠 데이터 1, 합칠 데이터 2, 합칠 데이터 3])
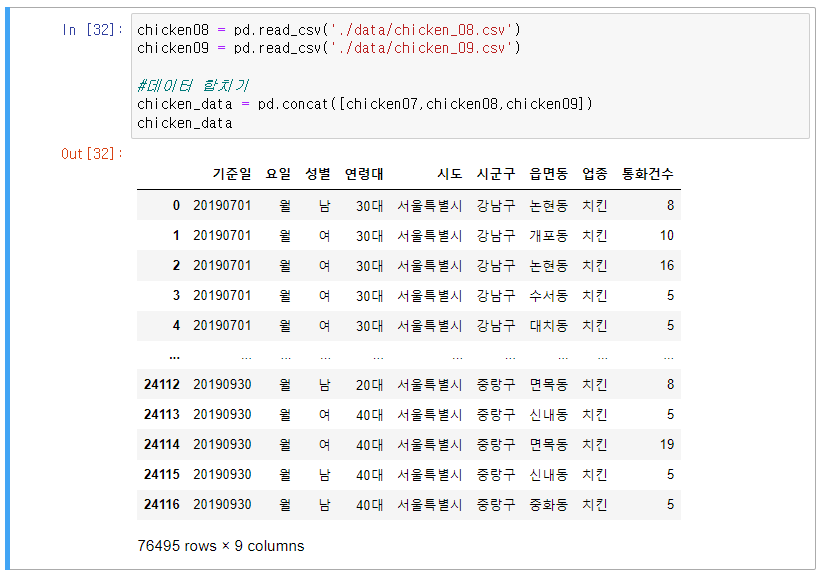
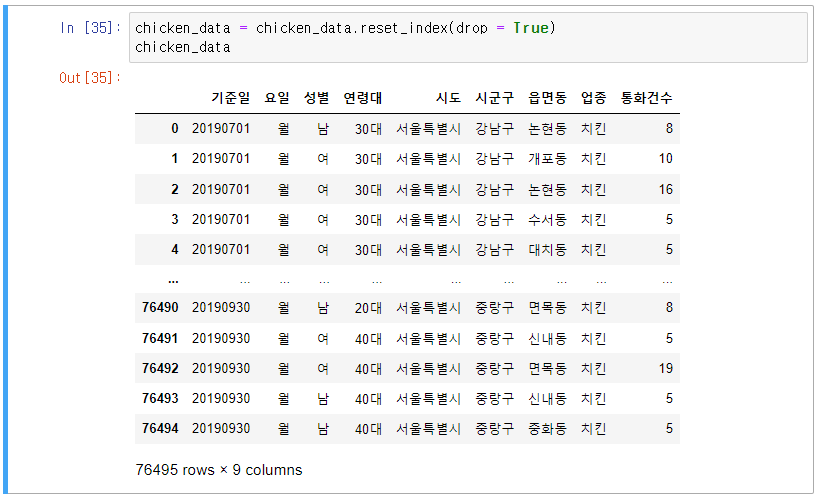
5] - 2) 합친 데이터의 index 재지정 : 합친데이터.reset_index(drop = True)
6] - 1) Matplotlib의 import
- Matplotlib란?
ㄴ시각화 라이브러리.
cf) 판다스(pandas)는 관계형 데이터를 다루는데 사용.
ㄴmatplotlib의 몸체가 매우 크기에 필요한 부분인 pyplot만 불러와 사용.

7] 시각화 하기 위해 데이터를 특정 기준으로 구분 혹은 정렬 :
ㄴ groupby('구분할 컬럼명')['구분해 보여줄 컬럼명'].원하는연산()

8] 데이터 시각화

9] 시각화 데이터의 폰트 확인 및 폰트 재설정

10] 시각화 데이터 정렬
1) 주문량에 따른 정렬

2) 요일 순서에 따른 정렬

[05:31] 스파르톤이 30분 남았다. 시각화 강의까지 딱 마치고 끝났으면 좋겠으니 어서 마저 달려야지..! 퀴즈만 두 개 풀면 되는것 같으니까 어서 화이팅..!
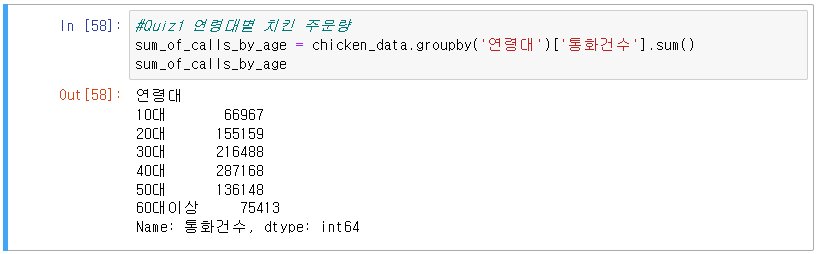
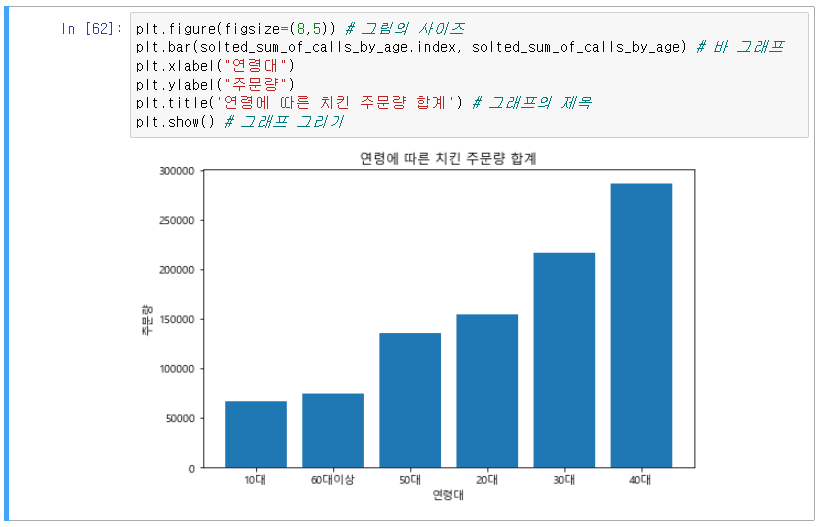
11] Quiz 1 : 연령대별로 치킨 주문량을 나타내기

1) 데이터 그룹화 : 연령별로 통화 건수 합쳐서 그룹화 하기
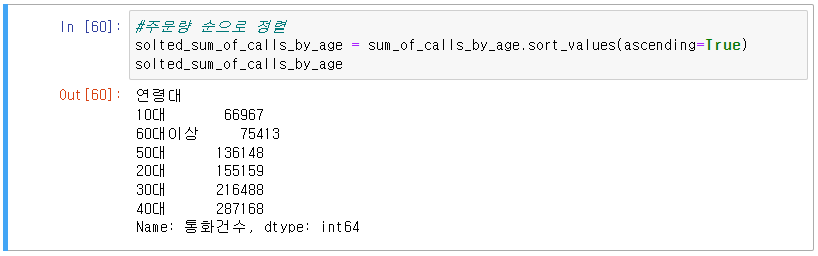
2) 데이터 정렬 : 통화건수가 작은 연령부터 큰 연령 순으로 그룹화된 데이터 정렬
3) 그래프 그리기
11] Quiz 2 : 서울에서 치킨은 어디에서 가장 많이 먹을까

1) 데이터 그룹화/정렬 : 시군구별로 통화 건수 합쳐서 그룹화 한 뒤 주문량에 따라 내림차순으로 정렬
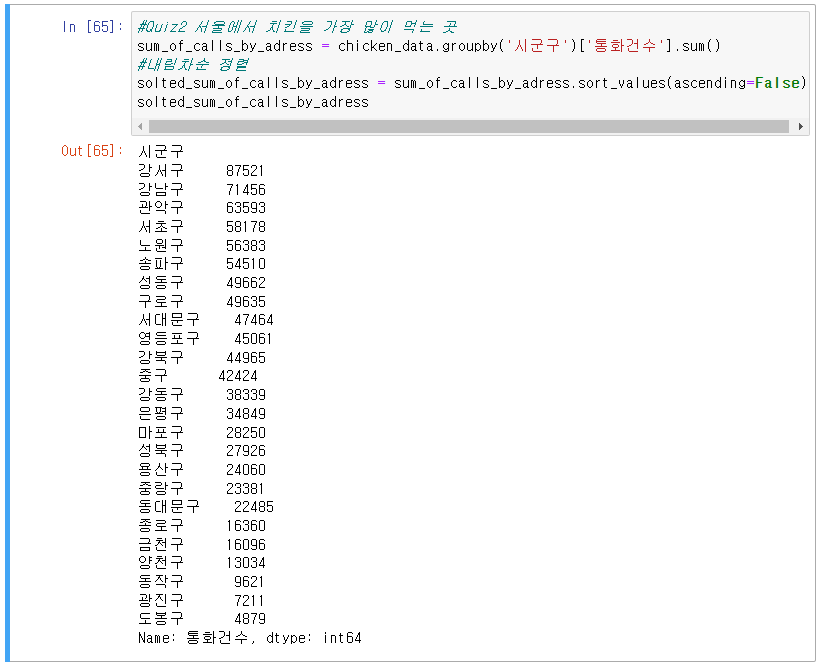
2) 그래프 그리기

11] Quiz 3 : 서울에서 치킨은 어디에서 가장 많이 먹을까

Q-1) 요일별로 피자 주문량을 정렬하여 오름차순으로 정렬 후 그래프 생성
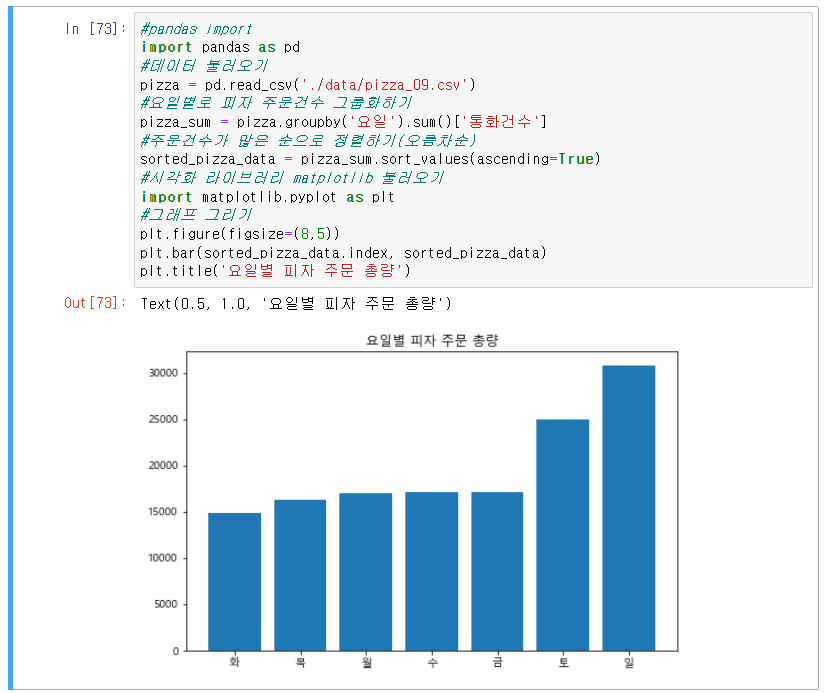
Q-2) 주소별로 피자 주문량을 정렬하여 오름차순으로 정렬 후 그래프 생성
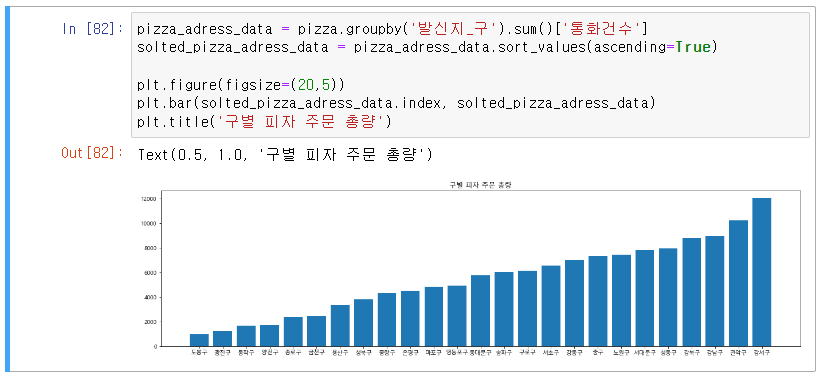
[05:58] 완강...!! 나..! 이제 파이썬으로 데이터 스크롤링도, 데이터 시각화도 할 슈 이써~~!!
소리가 안 들려서 폐막식 시작하는지도 몰랐는데, 매니저님들이 콕찌르기 하면서 돌아다녀주셔서 겨우 참가 할 수 있었다..!ㅋㅋㅋㅋ zep은... 해명하라..!

[06:00] 폐막식..! 대표님 튕김사태... zep은 해명하라...!ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ





'회고곡호고곡(회고록)' 카테고리의 다른 글
| 안녕- 2024, 안녕? 2025 (오랜만의 회고곡 새해 계획) (0) | 2024.12.31 |
|---|---|
| [AWS summit seoul 2024] 참가 일기 >-< (1) | 2024.05.18 |
| [20220328] 오늘의 일기 (0) | 2022.03.29 |
| [20220322] 오늘의 일기 (0) | 2022.03.22 |
| [20220321] 오늘의 일기 (0) | 2022.03.21 |
야나의 코딩 일기장 :) #코딩블로그 #기술블로그 #코딩 #조금씩,꾸준히
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[AWS summit seoul 2024] 참가 일기 >-<](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcfPbGC%2FbtsHu6pKYxM%2FAAAAAAAAAAAAAAAAAAAAAFv7V6NWU2IXmuF9u45IhegsQkzXc-XPYtnYTwdAU3R_%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DXkt8Gir%252B62%252FzretValGSBn6FFCc%253D)